Experts on the GDPR #4. Storing encrypted personal data in the cloud: What is the most secure option?




Let’s suppose that your company has a customer dataset where you store all customers’ personal data including contact information, list of purchases, invoices, etc.
- If they are the personal data of your own customers and you use them for your own purpose, you are considered as a data controller under the GDPR.
- Otherwise, if you process the customer data on behalf of another company, you are a data processor.
- The customers whose data are processed are the data subjects.
Whether you are a data controller or a processor, you have to protect the customer dataset in order to comply with the GDPR, as it clearly contains personal data.
For your organization’s operations, this dataset needs to be accessible to many of your employees from several devices, and your colleagues may also need to be able to collaborate on and share it with each other easily. This is where on-premises storage or different cloud-based solutions come into play.
To protect personal data, the GDPR highlights several technical measures, for example, encryption. However, there are many different ways to encrypt your data. In this blog post, our goal is to compare the different solutions to store and share encrypted data of your business, such as using on-premises versus different cloud-based services.
Which storage and encryption approach provides the best security and protection for personal data in the most frequent attack scenarios? To answer this, we have to address how possible it is to re-identify the persons from the encrypted dataset in case it gets leaked by a data breach. That is, we have to learn more about whether the stored encrypted personal data in these different approaches can still be regarded as readable, intelligible personal data which can be used to name and identify its owner.
The three options to store encrypted personal data
There are three main approaches to protect your customers’ stored and shared data with encryption.
- Local, on-premises storage of encrypted data: You encrypt the data and store the encrypted data by yourself locally on your servers.
- Cloud storage with server-side and in-transit encryption: You trust a cloud provider who encrypts your customer data and stores this encrypted data as well as the corresponding encryption and decryption key in a secure place. In that case, the provider can decrypt your data upon your request. Such services are offered by almost all cloud providers like Google, Dropbox, Microsoft, Amazon, etc.
- Cloud storage with client-side, end-to-end encryption: You encrypt the customer data on your side and store the encrypted data in the cloud. This way, you are the only one who can access the decryption key and no one else, not even the cloud provider. This is what we call client-side or end-to-end encryption and is offered by only a few vendors including Tresorit.
The GDPR’s aim is to protect people from the exposure of their personal data. According to the GDPR, personal data is defined as any information related to an identified or identifiable natural person. In the previous post, we showed that the definition of personal data depends on the context and eventually requires to check who can access the data and whether he or she can associate the data with any individual. In the above scenarios, this means that the encrypted data is personal if any plausible attacker, whoever it is, has reasonable chance to figure out the identity of data subjects whose data is encrypted. In general, plausibility depends on the motivation of the attacker (e.g., its incentives and disincentives to re-identify any data subject), and success probability depends on the technical difficulty of the attack (e.g., how easy is it to obtain the decrypted dataset?). Motivation and success probability are not totally independent. The easier an attack is the more motivated the adversary can be, however, we are not concerned with this dependence now.
To answer our main questions, let’s perform a high-level risk-analysis and discuss the plausibility and success probability of some attacks aiming to re-identify any individual whose data is encrypted in the above approaches. This will provide a clearer understanding of the advantages and disadvantages of each storage and encryption solution.
Approach 1: Local, on-premises storage of encrypted data
This solution is quite straightforward and secure only if your server, which might store the decryption key, or the terminal, which might be used to provide the passphrase to reconstruct the key, are well-protected. However, setting up a high level of protection is much harder than you would think. Firewalls, anti-virus, or other standard security products are usually not enough. Sophisticated targeted attacks can circumvent even mainstream security products and use spear phishing and social engineering to install some malware onto your system. For example, this can happen when one of your employees opens an innocuous attachment or click on a link in an e-mail which is forged by the attacker. When malware gets installed on any machine in your local network, they may exploit zero-day vulnerabilities of some software components of your system to get access to confidential files which might store the decryption key of your dataset. Alternatively, malware may log your keystrokes when you type the passphrase to decrypt your dataset. Even companies that invest heavily in data security are subject to such threats. So, why would it be hard (or implausible) in your case?
Approach 2: Cloud storage with server-side and in-transit encryption
Now, let’s see what happens if you upload your (unencrypted) customer data to a cloud provider who encrypts your dataset and stores it along with the encryption and decryption key in a secure place. Whenever you need your data, the provider decrypts them and sends the decrypted data back to you on a secure channel. How easy is it to re-identify persons if the datasets get leaked? Can your encrypted customer data be regarded as personal in this case?
Again, it depends on how easily the attacker, whoever it is, can get access to the decrypted customer data. For an external attacker (i.e., hacker), getting access to the provider’s server which stores the encrypted data might be technically more difficult than in the previous approach when you stored the encrypted data by yourself. This is simply because cloud providers are usually much more prepared for such attacks than you. Still, the likelihood of this attack is not negligible even in this case. The real difference is the attacker’s motivation; if it knows that the provider stores the decryption key (or the unencrypted data) of many users like you, the attacker might be much more motivated to target the provider.
Finally, potential (internal) attackers include the cloud provider itself as well as its employees who can easily get your decryption key. Although the provider does not have much incentive to snoop into your customer dataset due to the potential legal repercussions and reputation loss, a disappointed or financially motivated employee is somewhat more likely to do it.
Approach 3: Cloud storage with client-side, end-to-end encryption
This solution combines the advantages of the previous approaches; only you know the decryption key, but the data is safely stored by the provider. Now, I’ll suppose the worst-case, namely, the attacker somehow obtained a copy of the encrypted customer data. As shown above, in Approach 1, this step itself is not straightforward at all but certainly feasible as many infamous cases have exemplified in the recent past.
Now, can the attacker associate the encrypted data with one of your customers? In theory, no. The encrypted data can only be linked to a customer if the data gets successfully decrypted. In an ideal world, this is only possible if the attacker guesses your decryption key. If the key size is 256 bits and your key is totally random, the probability that the attacker guesses your key is about 1:2256. Just to illustrate how small it is, the number of all atoms in our galaxy is much less than 2256. So, we can certainly say that no attacker has reasonable chance to guess your key, which would mean that your encrypted customer data is considered as some uninterpretable totally random “garbage” data to anybody who does not have the key (including the attacker). Therefore, as long as the data cannot be decrypted, its breach is harmless to the data subjects.
However, the world is never ideal. First, your decryption key is generated from your passphrase or password. If your passphrase is easy to guess, the attacker can decrypt your encrypted customer data. If the attacker has reasonable chance to guess your passphrase, for example by installing a malware on your device which logs your keystrokes like in Approach 1, the encrypted data can be regarded as personal; if it gets leaked, data subjects can be re-identified. This also means that you have to be careful and take several precautions to minimize at least the risks of brute-force attacks, such as having strong passwords, uniquely generated for each service you use.
Second, the encryption algorithm used by you or your provider may be vulnerable to some attacks. This applies to all the three approaches, though. For example, the attacker may exploit some design flaws in the encryption scheme. Although such an attack is not totally unrealistic, it is quite unlikely nowadays especially if your provider applies standardized encryption schemes (like Tresorit). A second and more plausible way of breaking the encryption scheme is by exploiting implementation flaws in some software components used by the encryption scheme. These flaws (or any other backdoors) can be intentionally placed inside the code, for example, due to governmental solicitation. Still, this is unlikely if the provider uses open source implementations, or is transparent about their operations and how they manage government requests. However, exploiting unintentional implementation flaws (e.g., a typical buffer overflow) is much more plausible. Indeed, implementation flaws are unavoidable as long as humans develop software. The best that you and your provider can do is to use standardized algorithms and be transparent as much as possible, as well as regularly update software components.
Conclusion: Cloud storage with end-to-end encryption is winning
In the following table, you can see a concise summary of the above discussion on what are the plausibility and success probability of the two attackers we are looking at, the cloud provider (or its employees) and a hacker. We estimate the plausibility and the success probability of the most powerful attack of these attackers in this table. We measured both the plausibility and success probability on a scale of four likelihood values; low, moderate, significant, and large. For example, if any of the attacks has reasonable chance to occur and succeed, it has large or moderate plausibility and success probability. In this case, the encrypted data may be declared as personal because when it gets into the wrong hands, it can be used to re-identify the person it belongs to. 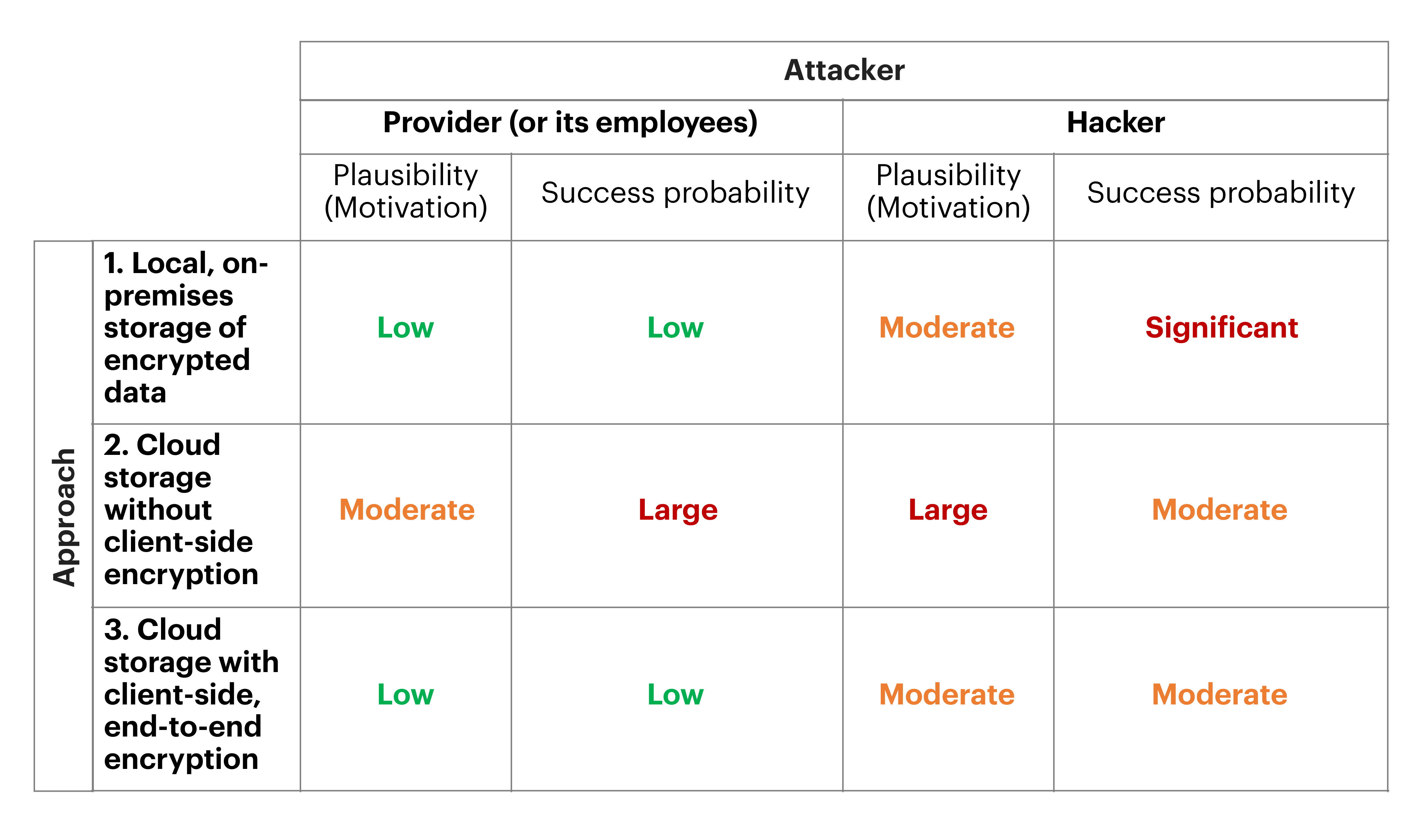
What is the best solution, then? As you can see, cloud storage with client-side, end-to-end encryption is the setting where the encrypted customer data is the less likely to be considered as personal and used for the re-identification of data subjects. This is mainly because the provider has no reasonable means to access the decryption key (and hence the decrypted customer data), and thus the hacker is less motivated compared to the case when the cloud provider stores the decryption key. Another good reason for using cloud storage instead of local storage is increased data safety; a cloud provider is much less likely to sustain data loss. This improves the availability and integrity of your data, which is also an explicit data protection principle in GDPR.
About the author
 |
Gergely Acs is an Assistant Professor at the Budapest University of Technology and Economics (BME), Hungary, and member of the Laboratory of Cryptography and System Security (CrySyS). Before joining CrySyS Lab, Gergely was a research scholar and engineer at INRIA, France. His research focuses on different aspects of data privacy and security including privacy-preserving machine learning, data anonymization, and data protection impact assessment (DPIA). He received his M.S. and Ph.D. degrees from BUTE. |


